

Program PLUczeK powstał pod czas prac nad Polsko-Ukraińskim Korpusem Równoległym (PolUKR) w 2009 r. Jest to edytor graficzny i konwerter do formatu XML, napisany w języku C#, oparty na działaniu programu do wyrównywania Hunalign. Program jest dostępny do ściągnięcia na stronie PLUczeK sourceforge.
Wymogi do instalacji
PLUczeK został stworzony dla pracy w środowisku Windows i był testowany na Windows XP Professional, Vista oraz Windows 7.
Dla poprawnego działania edytora, Hunalign musi znajdować się w jego katalogu wraz ze słownikiem z rozszerzeniem .dic w podkatalogu „data”. Opis formatu słownika można znaleźć na podanej stronie internetowej Hunalignu.
Oprócz tego, zalecane jest zainstalowanie platformy .NET: http://www.microsoft.com/net/download.aspx
Format danych wejściowych i wyjściowych
PLUczeK wymaga szczególnego formatu danych wejściowych – teksty już muszą być przed tym podzielone poprawnie na zdania i akapity, granica między akapitami jest oznaczana dwiema pustymi liniami, a granica między zdaniami – jedną. Plik musi mieć format .txt, kodowanie UTF-8 i nie zawierać więcej niż dwóch pustych linijek pod rząd. PLUczeK generuje przy zapisie trzy pliki – oprócz przetworzonych na XML plików tekstowych "wypluwa" także plik z wyrównaniem, tzw. stand-off alignment. Format plików jest zgodny z XML/XCES.
Praca z PLUczKiem, krok po kroku
- Krok 1: Wstępne wyrównanie automatyczne tekstów
- Krok 2: Wybór plików
- Krok 3: wczytywanie danych do tabeli
- Krok 4: Dzielenie na strony
- Krok 5: Modyfikacja wierszy
- Krok 6: Zapisywanie wyświetlonej tabeli do plików
- Krok 7: Ładowanie wcześniej stworzonych plików XML dla dodatkowej edycji
Krok 1: Wstępne wyrównanie automatyczne tekstów
Naciśnij przycisk 
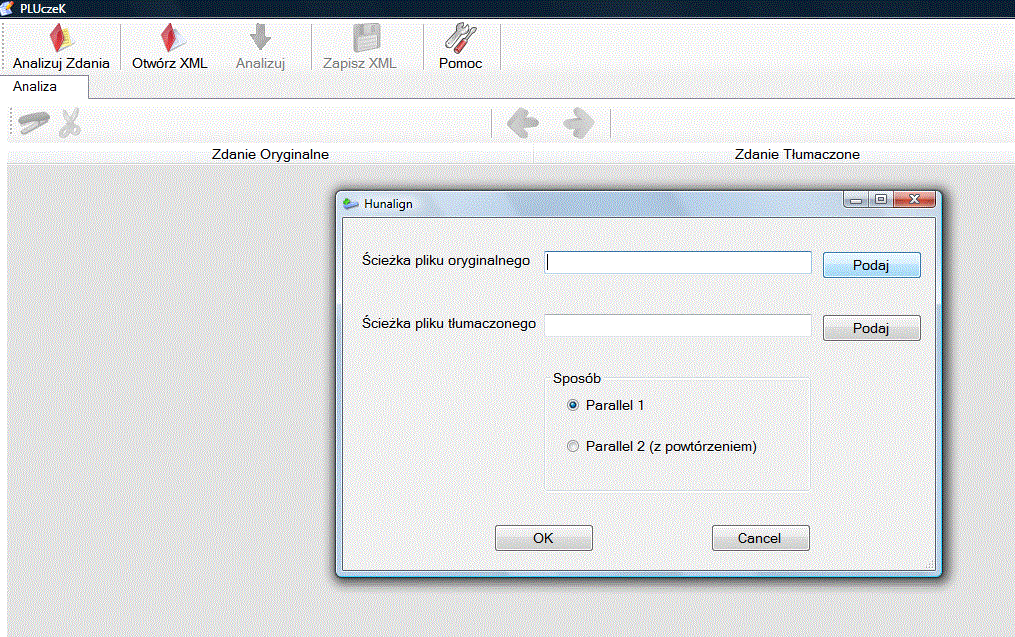
Krok 2: Wybór plików
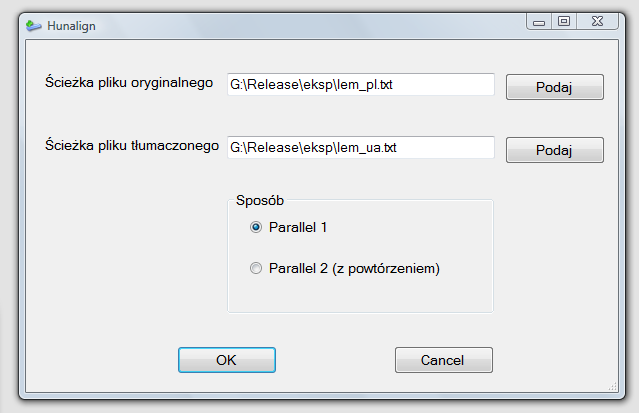
Podajemy ścieżki do 2-óch plików z tekstami oryginalnym i tłumaczony oraz wybieramy sposób przetwarzania tekstów przez Hunalign.
Sposób 1: hunalign.exe pus.dic plik_oryg.txt plik_tlum.txt -text > plik_1.txt
Sposób 2: hunalign.exe pus.dic plik_oryg.txt plik_tlum.txt -realign -text > plik_2.txt
Druga opcja zawiera dodatkowy cykl wyrównania i daje lepsze wyniki dla niektórych rodzajów tekstów.
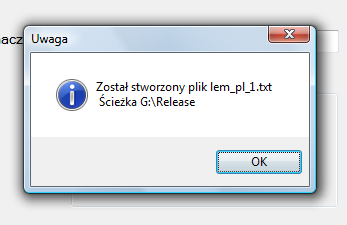
Krok 3: wczytywanie danych do tabeli
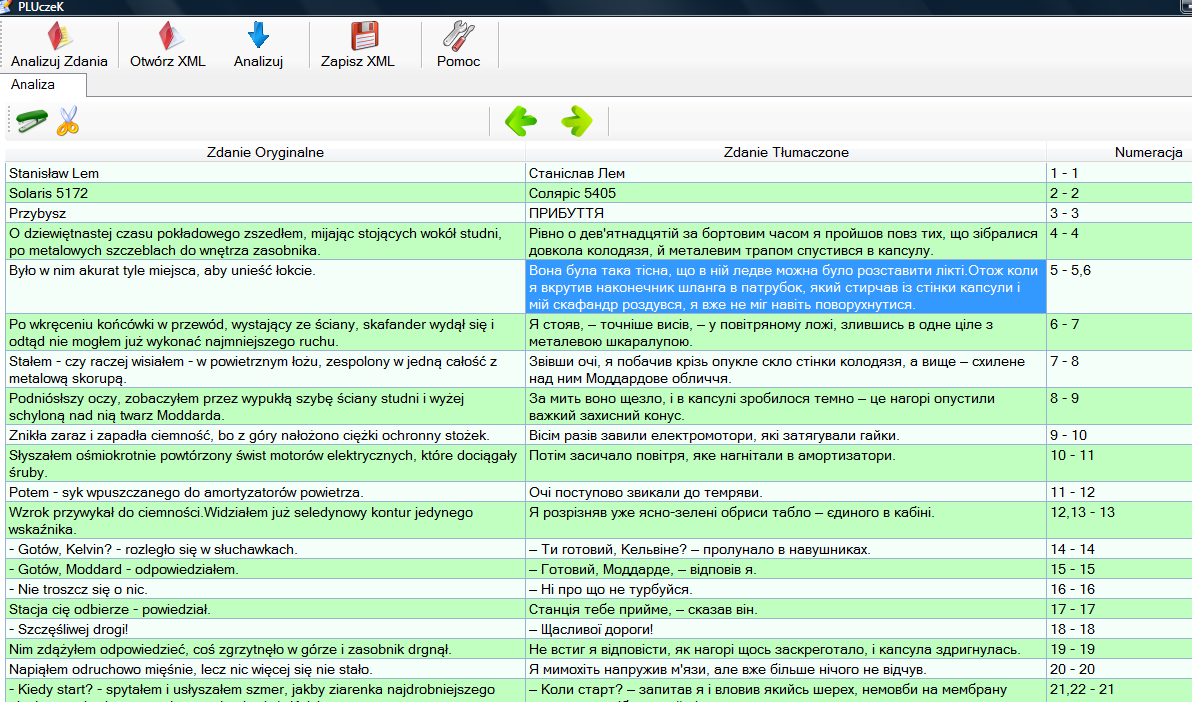
Następnie używamy przycisku  , który służy do załadowania danych (z trzech plików: dwa pliki podane przez użytkownika oraz jeden plik stworzony za pomocą programu Hunalign) na ekran, co możemy zauważyć na poniższym obrazku.
, który służy do załadowania danych (z trzech plików: dwa pliki podane przez użytkownika oraz jeden plik stworzony za pomocą programu Hunalign) na ekran, co możemy zauważyć na poniższym obrazku.
Krok 4: Dzielenie na strony
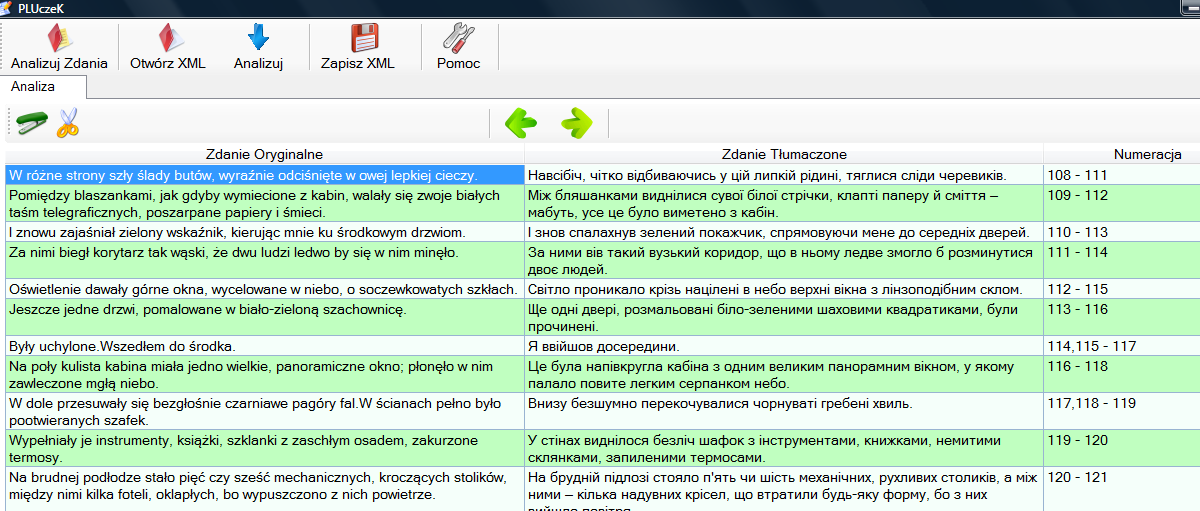
Jeżeli załadowany tekst ma więcej jak 100 wierszy, program automatycznie dzieli tekst na strony. Przechodzeniu do poprzedniej lub do następnej strony służą przyciski strzałek: 
 . Na przykład, po naciśnięciu widzimy kolejną stronę tekstu:
. Na przykład, po naciśnięciu widzimy kolejną stronę tekstu:
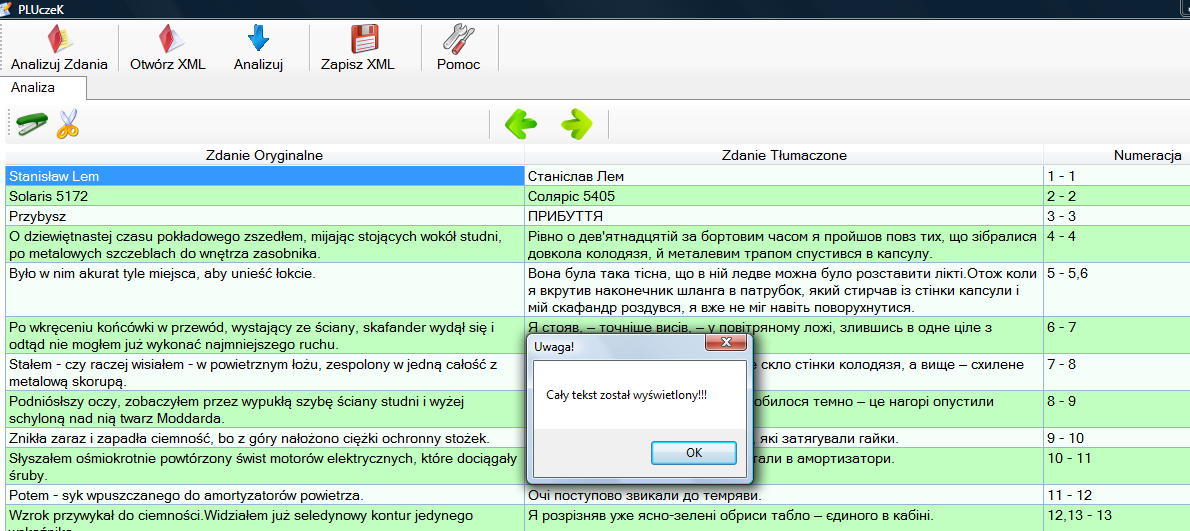
Uwaga! Będąc na pierwszej stronie, po naciśnięciu przycisku , dostaniemy poniższy komunikat:
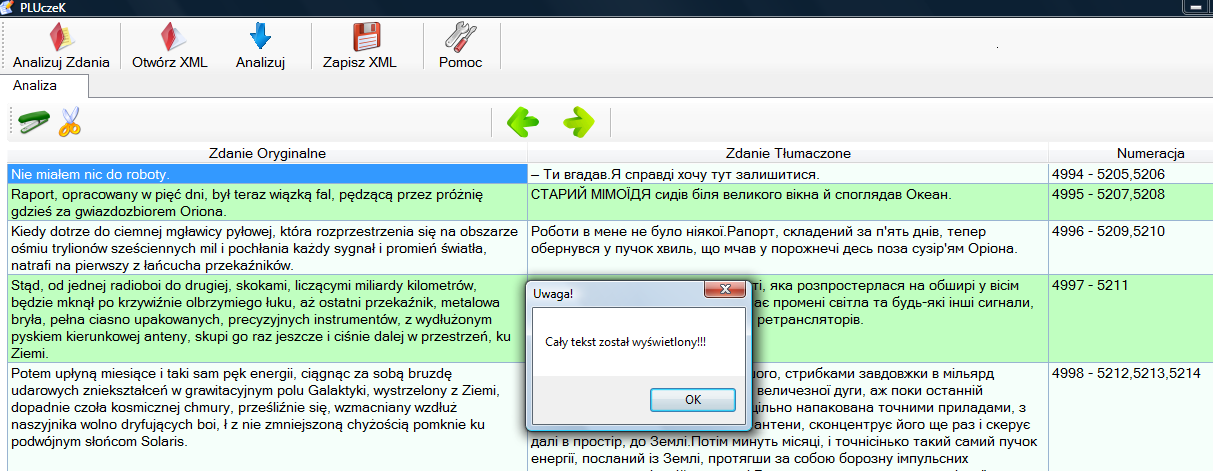
Będąc na ostatniej stronie, po naciśnięciu przycisku strzałki dostaniemy taki sam komunikat (zob. obrazek poniżej):
Krok 5: Modyfikacja wierszy
Przycisk  służy do dzielenia zdań z zaznaczonej komórki.
służy do dzielenia zdań z zaznaczonej komórki.
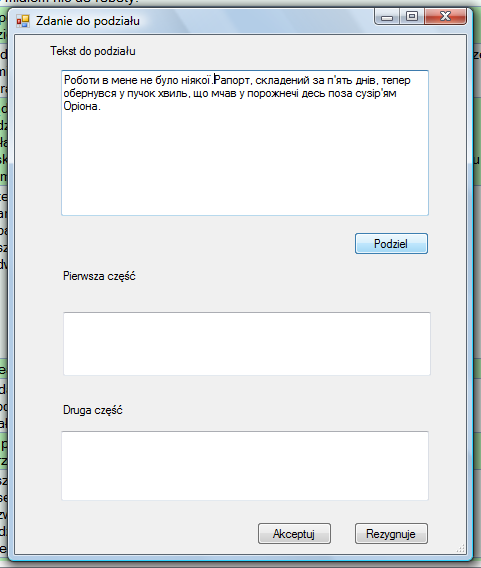
Np.: Po zaznaczeniu komórki klikamy na ten przycisk, po czym dostaniemy formularz do przycinania (zob. obrazek niżej).
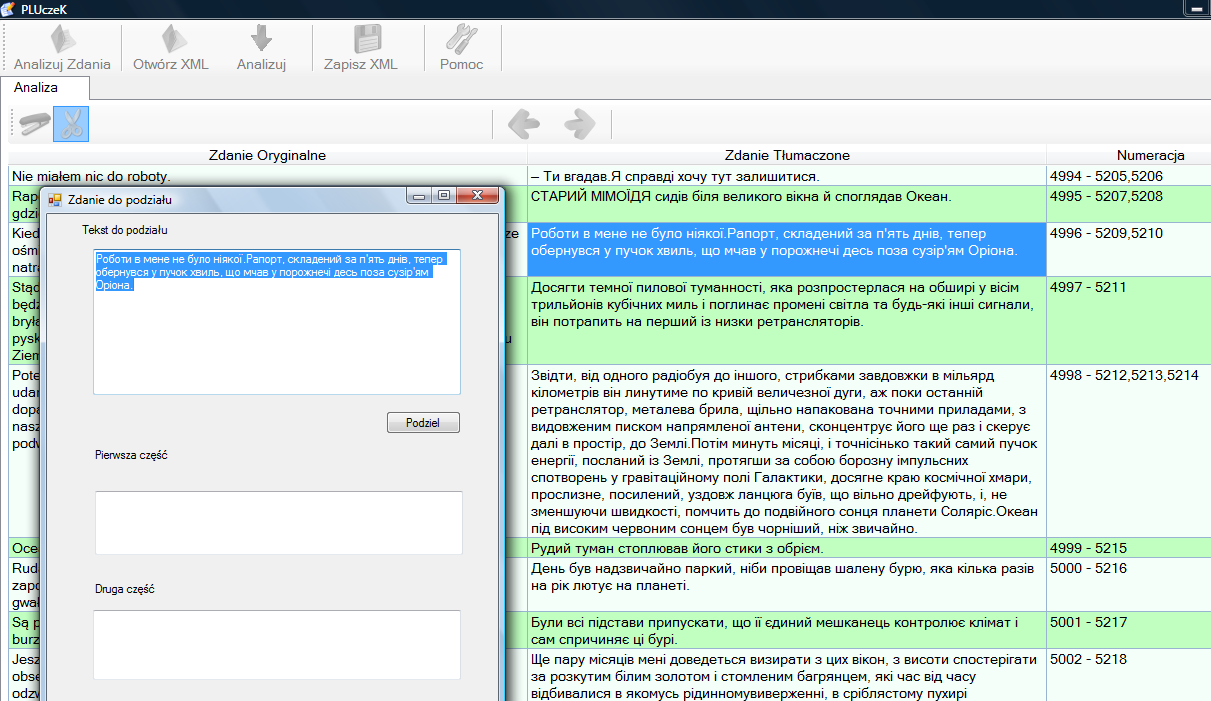
W komórce, gdzie znajduje się tekst do podziału, zaznaczamy kursorem miejsce, w którym trzeba podzielić dany tekst. Jeżeli zaznaczymy w nieodpowiednim miejscu, zostanie wyświetlony następny komunikat:
W przypadku, kiedy zaznaczymy poprawnie, dostaniemy taki efekt (po prawej stronie):
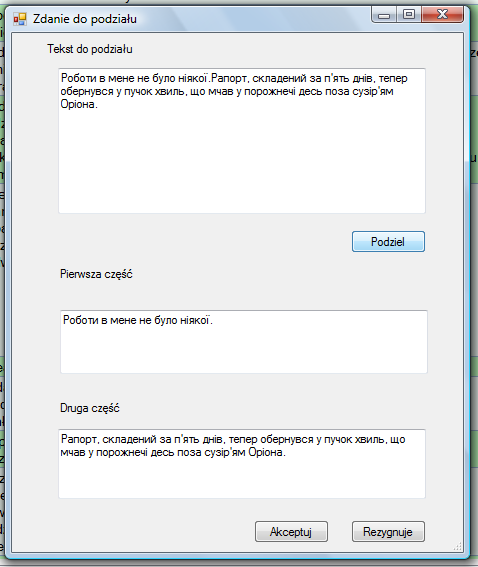 Po naciśnięciu przycisku "Akceptuj", zauważymy zmiany w tabeli:
Po naciśnięciu przycisku "Akceptuj", zauważymy zmiany w tabeli:
 Przycisk
Przycisk  służy do scalania tekstu z kilku komórek w jedną.
Na poniższym przykładzie pokazane jest zaznaczenie kilku komórek z tekstem, który chcemy połączyć.
służy do scalania tekstu z kilku komórek w jedną.
Na poniższym przykładzie pokazane jest zaznaczenie kilku komórek z tekstem, który chcemy połączyć.
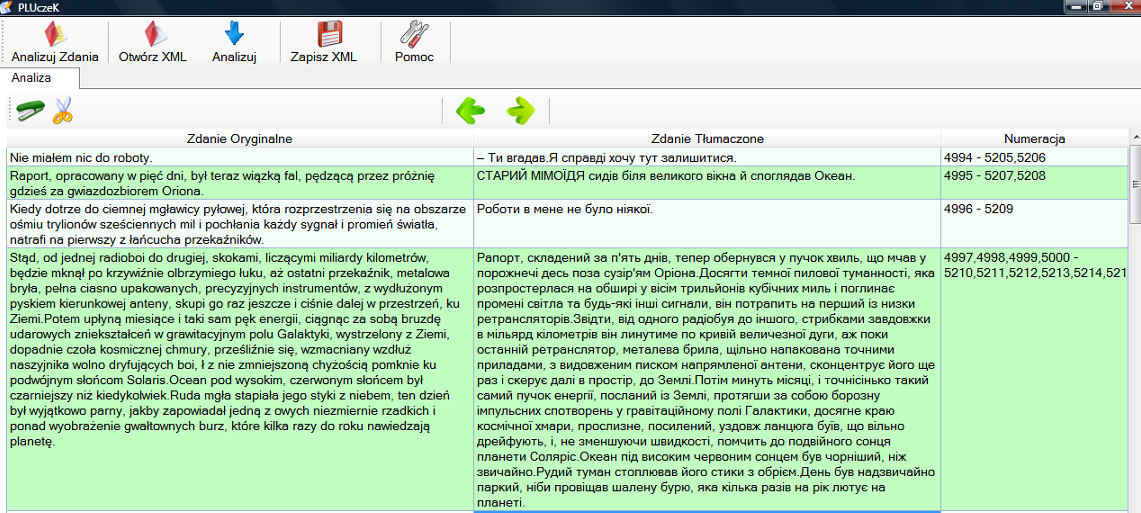
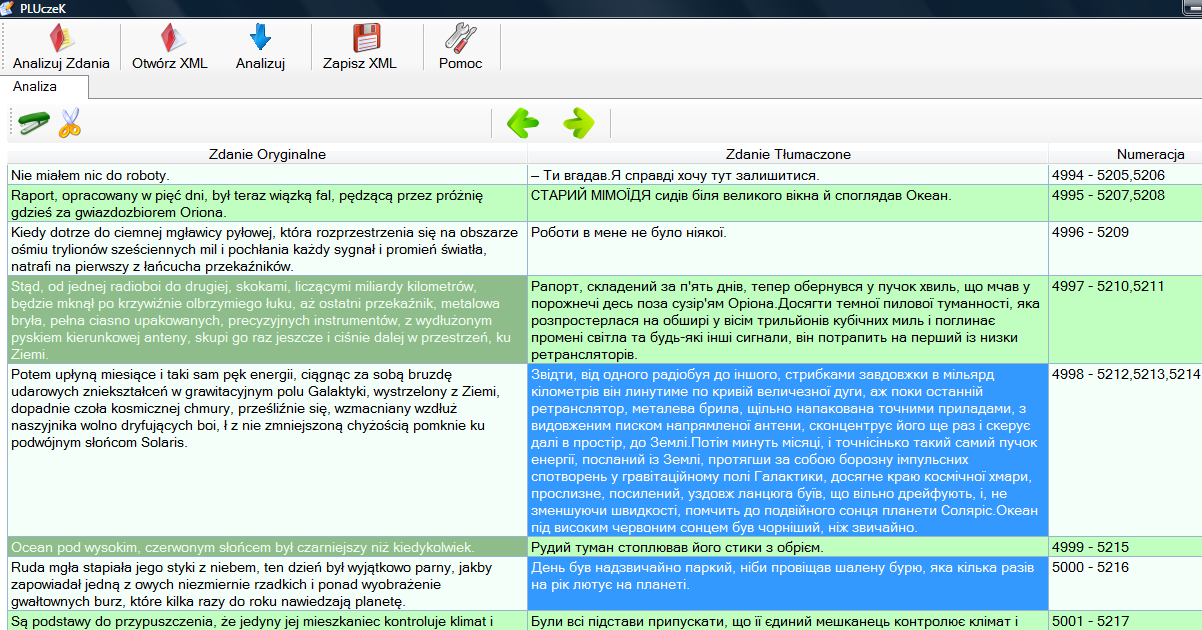 Po naciśnięciu przycisku możemy zauważyć, że teksty z zaznaczonych komórek zostały połączone w jedną.
Po naciśnięciu przycisku możemy zauważyć, że teksty z zaznaczonych komórek zostały połączone w jedną.
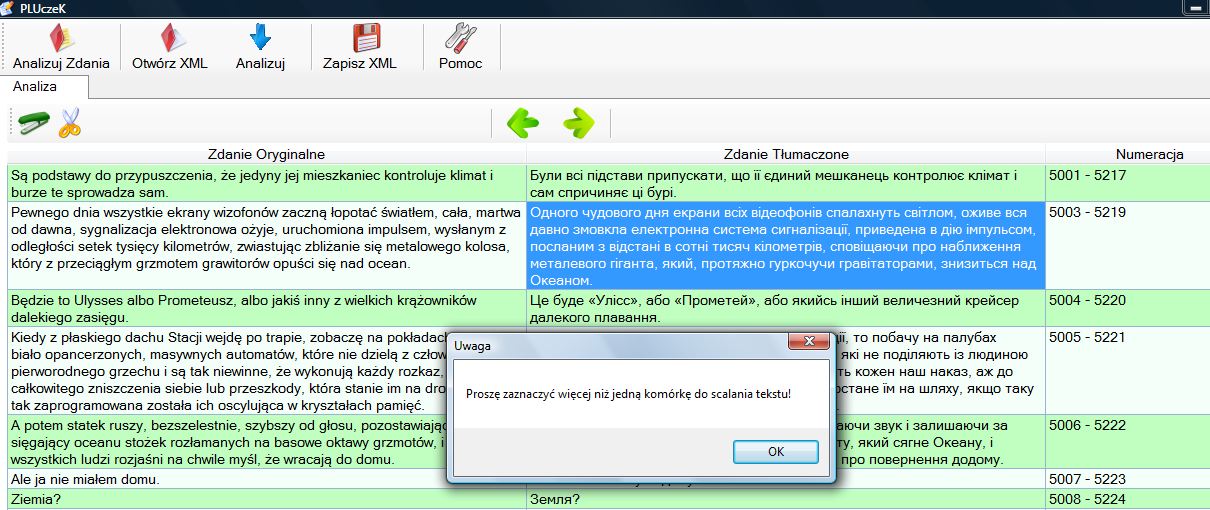
 Uwaga: Jeżeli zaznaczymy jedną komórkę i naciśniemy przycisk Scal, to zostanie wyświetlony komunikat (jak poniżej).
Uwaga: Jeżeli zaznaczymy jedną komórkę i naciśniemy przycisk Scal, to zostanie wyświetlony komunikat (jak poniżej).
Krok 6: Zapisywanie wyświetlonej tabeli do plików
Pliki wyjściowe generujemy za pomocą przycisku  . Musimy wskazać katalog, do którego powinny zostać zapisane pliki, oraz podać nazwę pliku głównego (przechowuje numerację), a dwa dodatkowe pliki, które automatycznie stworzą się z plikiem głównym będą przechowywać oddzielnie tekst oryginalny oraz tekst tłumaczony.
Szczególną uwagę należy zwrócić na końcówkę nazwy pliku, mianowicie cztery ostatnie znaki, które pojawią się przed rozszerzeniem .xml. Czwarty i trzeci znaki od końca muszą zawierać kod języka tekstu oryginalnego, tzn. tego, który się wyświetlał w PLUczKu po lewej stronie. Drugi i pierwszy od końca znaki są kodem języka tekstu tłumaczonego. Np. nazywając końcowy plik lemsolpluk, generujemy automatycznie trzy pliki XML: lemsolpluk.xml, lemsolpl.xml oraz lemsoluk.xml. Podane kody języków „pl” i „uk” pojawią się także w nagłówkach plików z tekstami, jako identyfikatory wersji językowych.
. Musimy wskazać katalog, do którego powinny zostać zapisane pliki, oraz podać nazwę pliku głównego (przechowuje numerację), a dwa dodatkowe pliki, które automatycznie stworzą się z plikiem głównym będą przechowywać oddzielnie tekst oryginalny oraz tekst tłumaczony.
Szczególną uwagę należy zwrócić na końcówkę nazwy pliku, mianowicie cztery ostatnie znaki, które pojawią się przed rozszerzeniem .xml. Czwarty i trzeci znaki od końca muszą zawierać kod języka tekstu oryginalnego, tzn. tego, który się wyświetlał w PLUczKu po lewej stronie. Drugi i pierwszy od końca znaki są kodem języka tekstu tłumaczonego. Np. nazywając końcowy plik lemsolpluk, generujemy automatycznie trzy pliki XML: lemsolpluk.xml, lemsolpl.xml oraz lemsoluk.xml. Podane kody języków „pl” i „uk” pojawią się także w nagłówkach plików z tekstami, jako identyfikatory wersji językowych.
Krok 7: Ładowanie wcześniej stworzonych plików XML dla dodatkowej edycji
Po zapisaniu danych do plików, możemy teraz wciągnąć dane, które już wcześniej były przetwarzane za pomocą tego programu. Dla tego służy przycisk  .
.
Uwaga: Ze względu na możliwość utracenia ważnych danych (np. może zapomnieliśmy zapisać lub rozmyśliliśmy się, chcemy dalej działać z tym tekstem a nie ładować następny) zostanie wyświetlony komunikat:
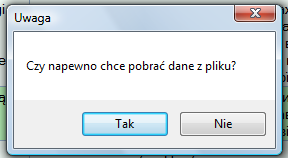
Jeżeli naciśniemy przycisk Tak, to tabela zostanie wyczyszczona i wyświetlone będą świeżo pobrane dane (w przypadku poprawnie podanego pliku!). Jeżeli jesteśmy pewni, to otwieramy wcześniej stworzony zestaw, podać nazwę pliku wyrównania (zawiera zestawienie numeracji zdań oryginalnych i tłumaczonych).
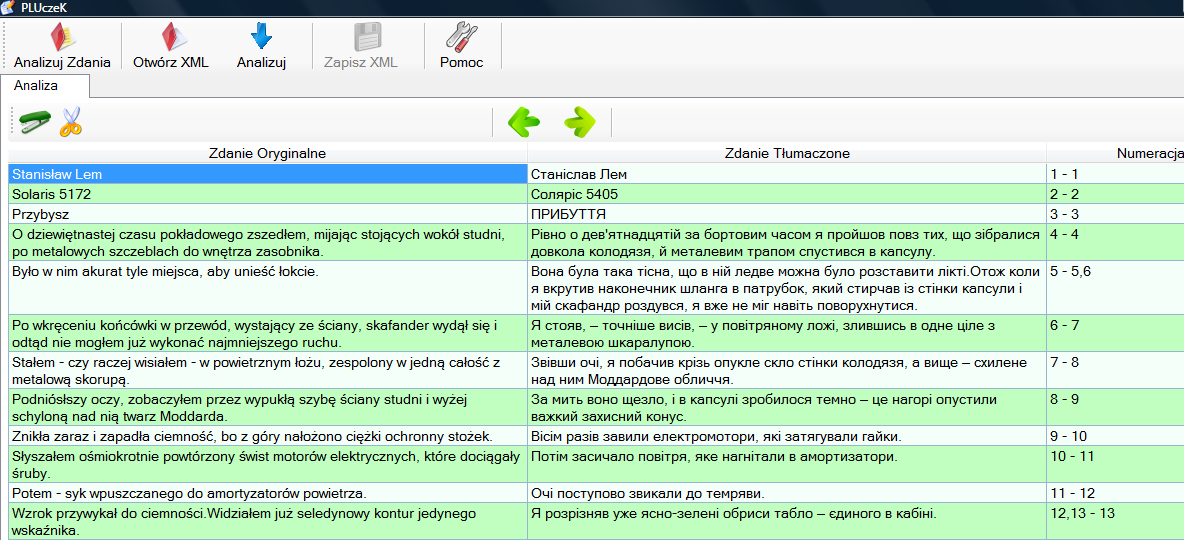
Na poniższym obrazku, możemy zauważyć, że program wyświetlił dane pobrane z podanych plików:
Jeżeli po modyfikacji wyświetlonych danych, zażyczymy sobie przejść do kroku 1, czyli Analizuj Zdania, zostanie wyświetlony komunikat:
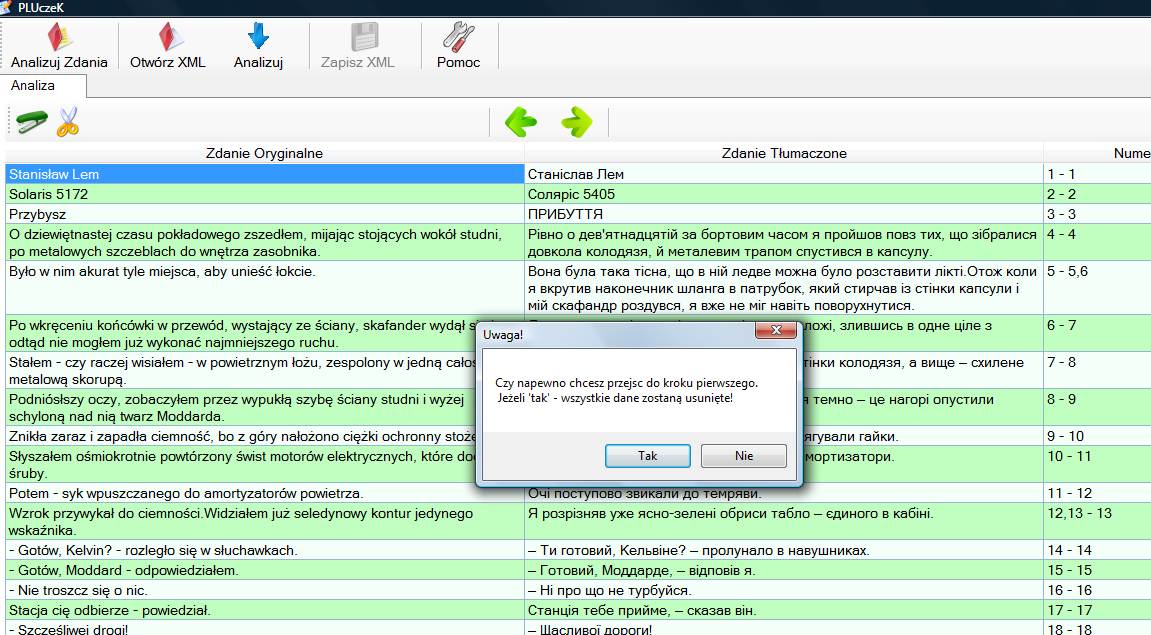
Jasne, jak zawsze, wyświetlany dla bezpieczeństwa ważnych danych/modyfikacji.
Życzymy miłej pracy i dobrych wyników!